
The Growing Need for Visual Workflow Design in Databricks
Databricks has emerged as the go-to platform for large-scale data processing, machine learning, and AI-driven analytics. With its powerful Spark-based architecture, seamless cloud integration, and robust performance capabilities, Databricks empowers enterprises to modernize their data engineering landscape. As organizations scale their data workflows, the need for enhanced usability and streamlined workflow management becomes more pronounced.
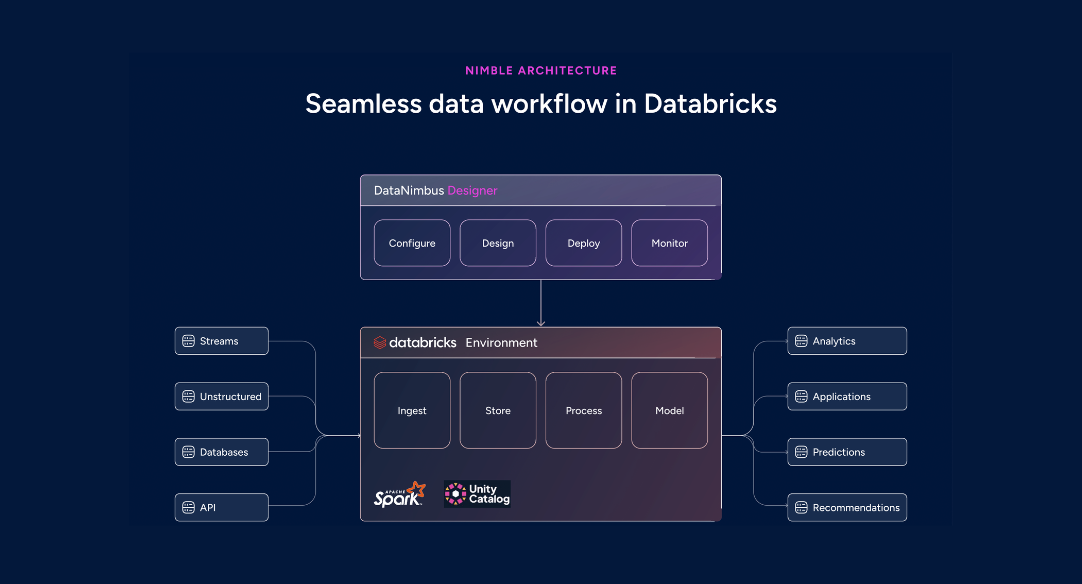
While Databricks provides a strong foundation for data engineering, many teams seek additional tools to simplify the orchestration and monitoring of complex ETL/ELT pipelines. DataNimbus Designer (DnD) complements Databricks by introducing a native visual workflow designer, enabling users to create, manage, and optimize data workflows with an intuitive, drag-and-drop interface—enhancing efficiency without relying on external ETL/ELT tools.
Why Running Databricks Workflows Natively Is Better Than External Tools
Many enterprises today rely on third-party ETL/ELT tools to orchestrate their data workflows. While these external solutions offer flexibility, they often introduce challenges related to cost, performance, and integration. As organizations scale, the inefficiencies of moving data between platforms, managing separate security configurations, and dealing with performance bottlenecks become increasingly evident.
Running workflows natively within Databricks, especially with a visual designer like DataNimbus Designer, offers a far more streamlined and optimized approach.
Eliminating Data Movement for Seamless Integration
One of the biggest drawbacks of external ETL tools is the need to move data between platforms, which increases processing time, storage costs, and complexity. Each data transfer introduces latency and potential security risks, making governance more challenging. Additionally, external tools often require separate authentication mechanisms and struggle to integrate deeply with Databricks-native capabilities like Unity Catalog, Delta Lake, and MLflow.
By contrast, running workflows natively ensures that data remains within Databricks throughout the pipeline. This eliminates unnecessary transfers, reduces costs, and maintains unified security and governance under Databricks’ policies. With seamless access to features like Delta Lake for optimized storage, Unity Catalog for centralized governance, and MLflow for model tracking, organizations can achieve a fully integrated, high-performance data ecosystem.
Optimized Performance and Cost Efficiency
External tools require dedicated infrastructure, leading to duplicate compute costs. Additionally, because they are not optimized for Databricks’ Spark-based processing, they often introduce inefficiencies that slow down large-scale workloads. The lack of deep integration means organizations must fine-tune performance manually, further increasing operational overhead.
A native approach eliminates these redundancies by leveraging Databricks’ own compute resources. With auto-scaling, performance tuning, and a pay-as-you-go pricing model, workflows can run efficiently without unnecessary infrastructure expenses. Native execution ensures that Spark clusters process data in parallel, significantly improving speed and scalability.
Accelerating Workflow Development with Visual Design
Building and managing complex ETL/ELT pipelines often requires extensive custom scripting, increasing the dependency on specialized data engineering teams. External tools, while offering some level of automation, lack the ability to integrate directly with Databricks notebooks, making debugging and monitoring cumbersome.
A visual designer within Databricks transforms workflow development by making it intuitive and accessible. Drag-and-drop interfaces reduce the need for manual coding, allowing teams to build workflows faster. Pre-built connectors and reusable transformation blocks further accelerate development, while seamless integration with Databricks notebooks ensures that teams can easily switch between visual and code-based development when needed.
Stronger Data Governance and Security
Security and governance become more complex when workflows span across multiple platforms. External tools often require separate role-based access control (RBAC) configurations and provide limited visibility into data lineage. This fragmented approach can create compliance risks, especially for organizations handling sensitive data.
Running workflows natively within Databricks ensures that governance remains centralized. Unity Catalog provides fine-grained access control, data lineage tracking ensures full transparency, and end-to-end monitoring allows organizations to maintain compliance effortlessly. With a unified security framework, businesses can enforce policies consistently across all workflows.
Real-Time Monitoring and Faster Debugging
When workflows fail, organizations need immediate insights to resolve issues and minimize downtime. External tools often lack deep visibility into Databricks job execution, making troubleshooting a slow and manual process. The inability to monitor execution in real time can lead to prolonged delays in identifying and fixing errors.
A native approach provides built-in workflow monitoring with interactive dashboards that offer real-time insights into execution status, data flow, and errors. Teams can track changes with version control, roll back when needed, and receive proactive alerts to address issues before they escalate. With integrated debugging tools, resolving failures becomes faster and more efficient.
The Future of Databricks Workflow Orchestration
As data workloads grow in scale and complexity, organizations need an orchestration solution that enhances—not complicates—their existing infrastructure. Running workflows natively within Databricks eliminates the inefficiencies of external tools, ensuring seamless integration, better performance, stronger governance, and faster development.
With a visual workflow designer like DataNimbus Designer, enterprises can unlock the full potential of Databricks, making data engineering more accessible, efficient, and cost-effective. The shift from external tools to a native-first approach isn’t just a matter of convenience—it’s a strategic decision to optimize data operations for the future.
Beyond Workflow Design: The DataNimbus Advantage
While Databricks Workflows offer a powerful way to orchestrate data processes, the addition of a visual designer takes it to the next level by:
- Lowering the barrier to entry for non-technical users.
- Enhancing collaboration across data teams.
- Providing a unified marketplace for connectors and reusable components.
By adopting DataNimbus Designer natively within Databricks, organizations gain the flexibility of a visual workflow builder while maintaining the power, performance, and security of Databricks’ ecosystem—without the downsides of external tools.
If you’re looking to simplify ETL pipelines, accelerate AI adoption, and optimize cost-efficiency, it’s time to embrace native workflow orchestration with DataNimbus Designer on Databricks. Ready to transform your data workflows? Let’s talk!


