

Introduction
Turnpoint Services is an equipment (HVAC, electrical, and plumbing services company) services company based in the US. It boasts a growing list of reputable service brands with decades of experience serving residential and commercial customers. The company has been expanding at a fast pace with inorganic growth, adding new brands every other month through acquisitions. However, due to the swift business growth, there was a pressing need for a data solution that could help manage the overwhelming amount of data coming in daily. To address this issue, Turnpoint partnered with DataNimbus to build a data lake solution from scratch using the Databricks Lakehouse platform.
Over the past three years, there have been multiple data engineering and data science projects to build scalable data and ML pipelines aligned with the Turnpoint business goals following the initial project’s success.
Use Cases
1. Machine Learning and MLOps
Business Challenge
Turnpoint Services initially deployed demand forecasting using basic models and manual operations. However, this approach encountered several obstacles that hindered the company’s ability to make rapid, informed decisions:
- Scalability Limitations: The manual nature of existing forecasting models couldn’t keep pace with Turnpoint’s accelerating growth, leading to operational bottlenecks and delays in decision-making.
- Operational Inefficiency: Labor-intensive manual processes for training models consumed valuable time, increasing the risk of errors and causing the insights generated to become outdated quickly.
- Lack of Automation: The absence of a robust MLOps framework meant that the models weren’t self-correcting, requiring continual manual oversight to maintain performance and accuracy.
Solution
To address Turnpoint Services’ demand forecasting challenge, DataNimbus executed a fourfold strategy, all constructed on the Databricks Lakehouse platform:
- Data Ingestion Pipelines: An automated ingestion pipeline was implemented to fetch batch data from ServiceTitan and weather data APIs. This pipeline streamlined data availability, setting the stage for machine learning processes.
- Model Training/Retraining Pipeline: Using Databricks AutoML, a dedicated pipeline was established to train and retrain hundreds of models. The system was calibrated to forecast the call and job counts for upcoming weeks.
- Prediction Pipelines: A specialized prediction pipeline, set to execute daily, was rolled out to offer hourly forecasts for the next 14 days.
- Model Drift Handler Pipeline: Integrated with MLflow, this oversight mechanism monitors model performance metrics. Should a model underperform, the system autonomously triggers a retraining sequence to ensure ongoing accuracy.
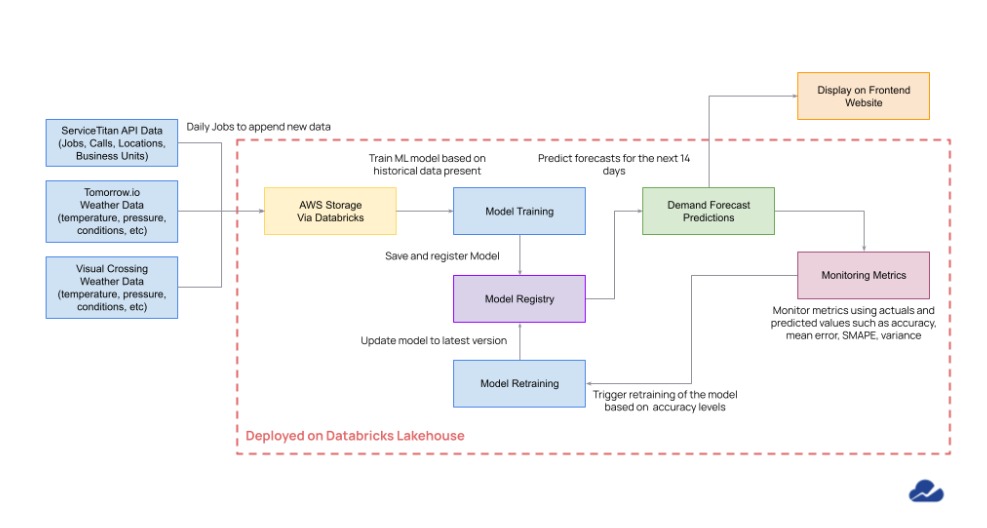
- Efficiency Boost: The automated forecasting process on Databricks has dramatically streamlined data workflows. This acceleration has reduced the time lag between gathering data and making informed decisions, giving Turnpoint a speed advantage in its operations.
- Dynamic Adaptability: By incorporating a model drift handler, the system can automatically detect and adapt to shifts in data trends. This feature ensures that the predictive models retain their accuracy over time, even when faced with fluctuating data patterns.
- Cost Savings: The high degree of automation introduced by DataNimbus eliminates the manual labor previously needed for data forecasting. This has led to substantial cost savings, as the need for continuous manual intervention is virtually eradicated.
- Scalability: Designed with scalability in mind, the pipelines can accommodate an influx of data without compromising performance. This makes the solution well-suited for Turnpoint’s ever-evolving business needs and future growth plans.
2. Data Engineering
Data engineering was one of the initial engagements DataNimbus started with Turnpoint. The core solution of this project involved building a data lakehouse platform that would automate and scale the data pipelines the client uses for data visualization and analytics.
Business Challenge
As a company that offers home services, the client deals with customer information, appointment bookings, and memberships. To manage this data, TurnPoint used cloud-based data providers like ServiceTitan alongside a third-party tool for visualization. Every day, CSV files had to be downloaded from several reports and transferred to the business team’s data visualization tool. The process was time-consuming, and the data was only stored in the cloud provider, making it difficult for teams to consume.
This fragmented approach led to several key issues:
- Scalability Concerns: Quick growth overwhelmed the current data setup, causing delays and limiting quick decisions.
- Operational Inefficiency: Manual data handling wasted time and risked mistakes, aging the insights.
- Data Silos and Inconsistency: Data was stuck in separate places, making it difficult to get a complete and reliable view.
- Limited Real-Time Decision-Making: The system couldn’t provide instant data, affecting quick, informed choices in the field.
Data Lakehouse Initiative
To holistically manage the data ingestion, storage, and availability, DataNimbus proposed constructing a Data Lakehouse solution. This modern architecture would enable seamless ingestion from multiple cloud-based data providers like ServiceTitan, facilitating required transformations and aggregations before centrally storing the data for easy access.
- Initially, the team leveraged the Databricks platform, integrated with Amazon Web Services (AWS) for robust cloud capabilities. Necessary configurations were implemented for S3 buckets to act as resilient storage components.
- A best-practice approach was adopted using the Medallion Architecture for the data pipelines. Data from ServiceTitan, which was the primary data source at that time, was periodically ingested. Raw data was first loaded, followed by essential transformations, and the polished “gold” tables were securely housed in the pre-configured S3 buckets.
- The enriched data tables were plugged into Turnpoint Service’s visualization tool, enabling advanced dashboarding and analytics capabilities.
Expanding Data Sources
Building on the pilot’s success, DataNimbus was further tasked with broadening the data landscape to include diverse data points. For example, Google Reviews was integrated for customer sentiment analysis, while Samsara was tapped for real-time geolocation tracking of field technicians.
Most of these additional data sources utilized API-based integrations, similar to the initial ServiceTitan setup. DataNimbus designed multiple workflows capable of ingesting and processing millions of records in real-time, further amplifying the solution’s scalability and versatility.
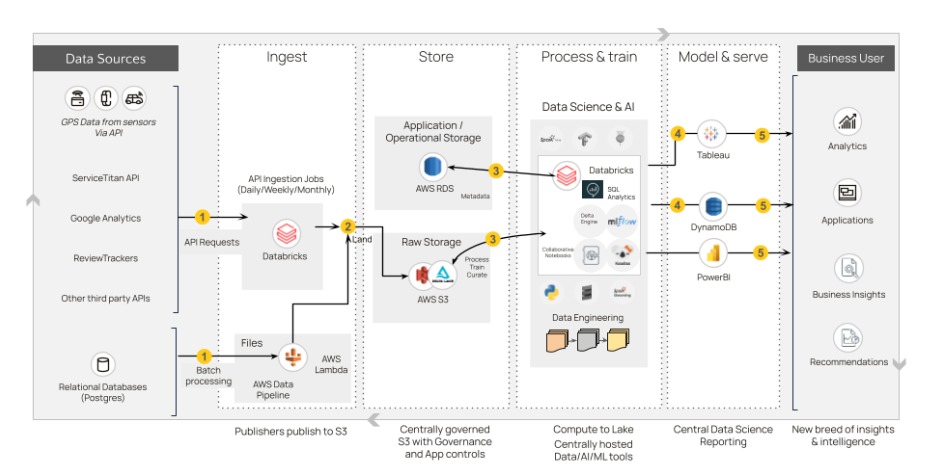
Value Creation
- Scalability: The lakehouse solution built on Databricks ensures that Turnpoint Services can quickly adapt to increasing data demands. Whether it’s acquiring new brands or expanding service offerings, the architecture is designed to handle growth seamlessly. This significantly impacts the company’s agility, enabling it to make data-driven decisions without worrying about infrastructure limitations.
- Automation: Before this solution was implemented, the client had to manually download and transfer CSV files, which was time-consuming and error-prone. Automating this process has liberated valuable person-hours, allowing staff to focus on higher-value tasks like analytics and customer engagement. This improves operational efficiency and speeds up the time to insight for critical business decisions.
- Single Source of Truth: DataNimbus’s centralized data storage approach has eliminated data silos within Turnpoint Services. Teams across the organization can now access the same up-to-date, reliable data. This enhances the quality of insights generated from the data, improves collaboration between departments, and dramatically reduces the chances of data inconsistencies affecting business decisions.
- Real-time Analytics: Integrating real-time geolocation data from sources like Samsara offers Turnpoint an immediate view of field operations. This real-time insight allows for proactive management of technicians and resources, resulting in improved customer satisfaction and operational efficiency. It takes Turnpoint’s service quality to a new level by enabling them to respond to situations as they occur rather than after the fact.
Conclusion
Glossary
- Data Lakehouse: A hybrid data architecture combining features of data warehouses and data lakes for optimal performance and flexibility.
- Medallion Architecture: A structured approach for managing data at varying stages—raw, curated, and “gold”—to improve reliability and accessibility.
- Model Drift: The phenomenon where machine learning model performance declines due to changes in data patterns over time.
- MLOps: A practice that blends machine learning, data engineering, and DevOps to streamline the end-to-end machine learning workflow.











